How it works
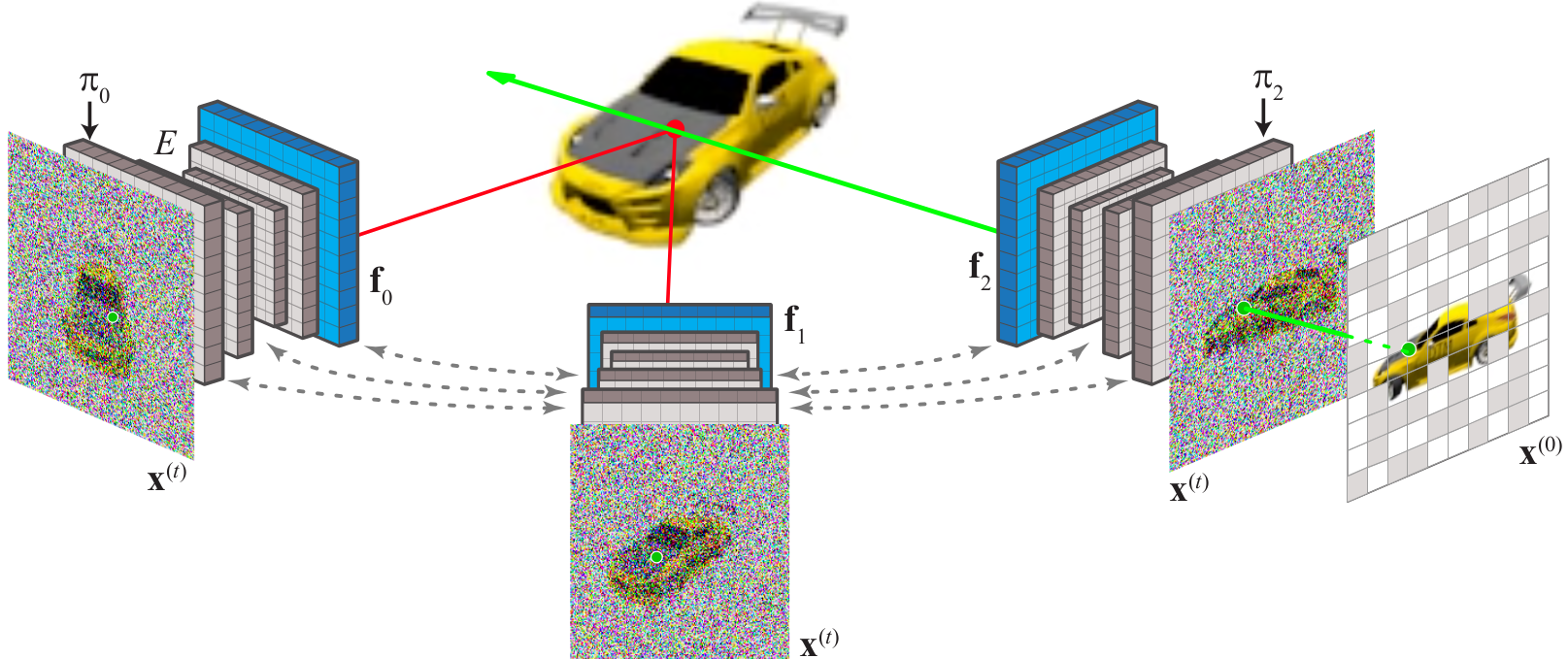
Our neural scene representation IB-planes defines 3D content using image-space features. Each camera $\pi_v$ is associated with a feature-map $\mathbf{f}_v$ (blue); together both parametrise a neural field that defines density and color for each 3D point $p$ (red dot). This can be converted to an image using standard NeRF ray-marching.
We incorporate this representation in a diffusion model over multi-view images. At each denoising step, noisy images $\mathbf{x}^{(t)}$ are encoded by a U-Net $E$ with cross-view attention (gray dashed arrows), that yields pixel-aligned features $\mathbf{f}_v$ (blue). To render pixels of denoised images (only one $\mathbf{x}^{(0)}$ is shown for clarity), we use volumetric ray-marching (green arrow), decoding features unprojected (red lines) from the other viewpoints.
For 3D reconstruction, we replace one or more of the noisy images with noise-free input images and perform conditional generation. The noise in the other images encodes the content of regions that are not visible in the input images, ensuring all parts of the scene are coherent and contain plausible details.
Results
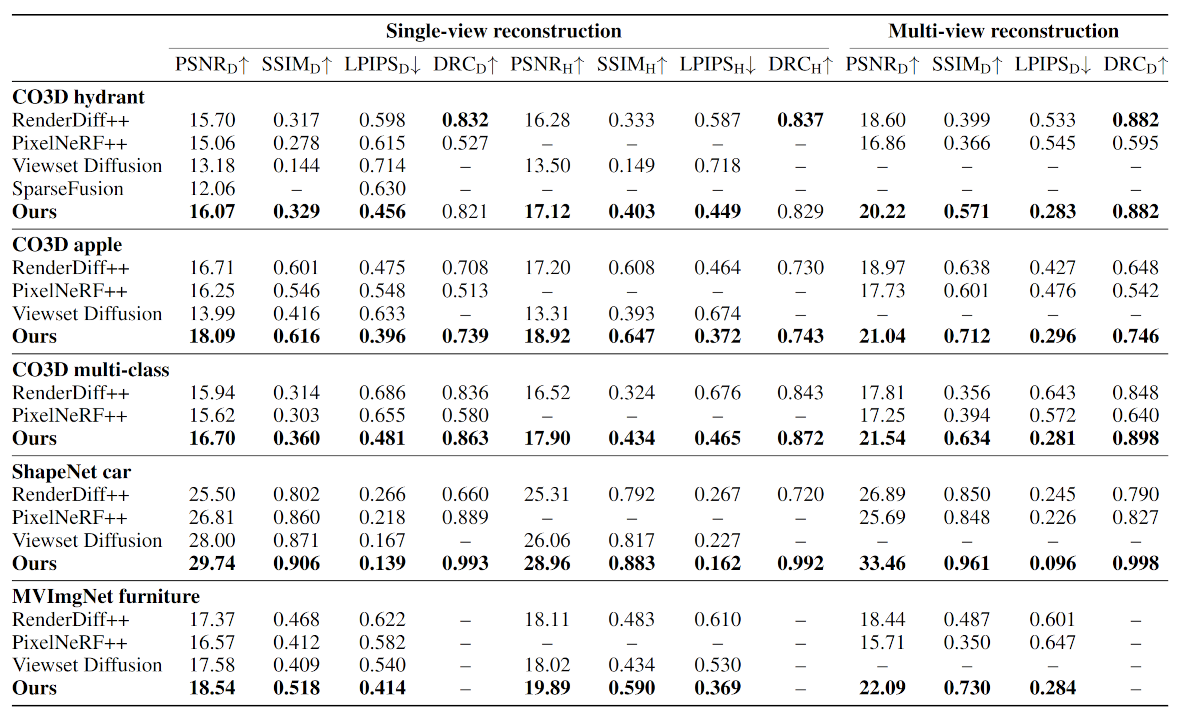
Quantitative results on 3D reconstruction
We compare GIBR with several state-of-the-art methods for 3D reconstruction from one or few images. We measure performance using pixel reconstruction metrics on held-out images. Metrics suffixed D are calculated directly on the denoised images, while metrics suffixed H use renderings from other viewpoints. Bold numbers are the best.
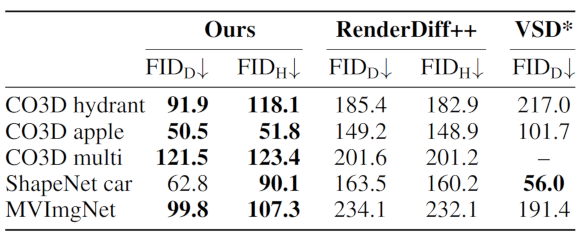
Quantitative results on generation
We compare GIBR with two other methods that generate 3D scenes via 3D-aware image diffusion. GIBR outperforms these baselines according to Frechet Inception distance, on both the denoised images (suffix D) and renderings from other viewpoints (suffix H).
Citation
@inproceedings{anciukevicius2024denoising,
title={Denoising Diffusion via Image-Based Rendering},
author={Titas Anciukevi{\v{c}}ius and Fabian Manhardt and Federico Tombari and Paul Henderson},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=1JbsdayvhO}
}